I have been a speaker at two major psychiatry conferences last year in Washington DC and Amelia Island FL, on the topic of AI and Big Data in psychiatry (see slide presentation below). What I found in speaking with conference attendees is that the psychiatrists and behavioral health researchers found it difficult to make the connection on how to implement AI into actual psychiatry use cases. In other words, what’s the point of even introducing AI to psychiatry if they can’t even picture how it will be used in psychiatric practice?
AI Psychiatrist?
So how do we utilize AI in psychiatric practice? This is a valid question, and those of us at the cutting edge of this emerging field need to clarify exactly how AI can be implemented into a psychiatric practice. Otherwise, AI and psychiatry will just be left to Sci-Fi movies, such as seen in the movie I, Robot (2004 film), featuring psychiatrist and advanced robotics expert Dr. Susan Calvin:
Det. Spooner : So, Dr. Calvin, what exactly do you do around here?
Dr. Susan Calvin (Bridget Moyanahan) and Det. Del Spooner (Will Smith) in I, Robot (2004 film)
Dr. Calvin : My general fields are Advanced Robotics and Psychiatry. Although, I specialize in hardware-to-wetware interfaces in an effort to advance U.S.R.’s robotic ahthropomorphization program.
Det. Spooner : So, what exactly do you do around here?
Dr. Calvin : I make the robots seem more human.
Det. Spooner : Now wasn’t that easier to say?
Dr. Calvin : Not really. No.
Although I’m not saying that having an AI psychiatrist making AI robots seem more human is within reach, I’m going to show you actual use cases for psychiatry which AI can solve now. Given I’m both an MD psychiatrist and an MSc data scientist, I’m well-positioned to connect these seemingly different domains of psychiatry and AI.
Now let’s look at the following three psychiatry use cases for AI that we can implement now:
Predictive Modeling
Predictive modeling is about using historical data to build machine learning algorithms to predict future events. For this AI application in psychiatry, we will utilize the following psychiatry use case: we will predict which treatment is likely to work for a patient with depression.
Use Case 1: let’s look at patients with depression who responded to treatment (see Figure 1 below):
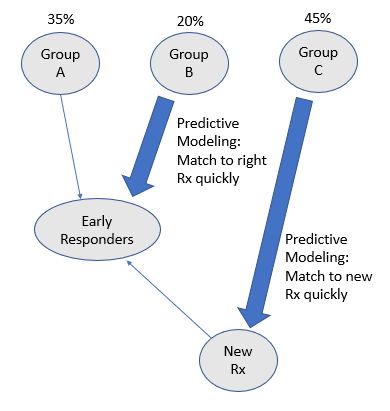
- Group A represents those patients who responded in the first two years of treatment (Early Responders)
- Group B represents those patients who responded between two to five years of treatment (Late Responders)
- Group C represents those patients who continued to suffer even after five years of treatment (Non-Responders)
Before AI, psychiatrists would utilize clinical intuition, presentation, and history of the patient to predict which group the patient belonged- Group A, B, or C. Sadly, this is performed with much guess work, given the subjective nature of such classification task. However, utilizing AI with predictive modeling would help improve the matching of the patients to the right group, and hence the right treatment quickly, so that the Late Responders in Group B will become the Early Responders in Group A.
Furthermore, utilizing AI with predictive modeling will help identify the Non-Responders in Group C quickly, so that a new treatment can be developed for them. And once this new treatment is found for the Group C patients, they would soon become the Early Responders in Group A. So as you see, utilizing AI via predictive modeling can help to improve the overall treatment of depression (via accurate classifications into Groups A, B, or C), with the end result that all patients become Early Responders.
Computational Phenotyping
Computational phenotyping is about utilizing computational techniques such as machine learning to classify illnesses and other clinical concepts from the data itself. The “traditional” approach to phenotyping psychiatric disorders involves using supervised learning and relies on domain experts (psychiatrists), and has two main limitations:
- Requires highly skilled humans (psychiatrists) to supply correct labels, and hence limits its scalability and accuracy, and
- Relies on existing clinical descriptions (e.g the DSM-5), and limits the sorts of patterns/subtypes that can be found.
For instance, the traditional approach to phenotyping psychiatric disorders may fail to acknowledge that a psychiatric disorder treated as a single condition may really have several subtypes with different phenotypes, as seems to be the case with depression and schizophrenia. Some recent papers cite successes instead using unsupervised learning to finding novel patterns with regards to grouping psychiatric disorders based on Kraepelin-like observations of prognistic similarity, but instead of grouping the patients manually as Emil Kraepelin did, unsupervised learning uses computational power and clustering machine learning algorithms to group the patients. This unsupervised learning approach utilizing computational power and machine learning clustering algorithms shows great potential for finding patterns in Electronic Health Records that would otherwise be hidden and that can lead to greater understanding of psychiatric conditions and treatments.
Use Case 2: let’s look at patient data in Electronic Health Records and turn raw patient data into psychiatric phenotypes/concepts (see Figure 2 below):
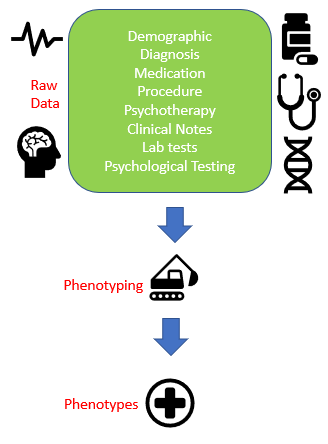
- The input to Computational Phenotyping is the raw patient data.
- The raw patient data consists of many different sources, such as demographic information, diagnosis, medication, procedure, lab tests, and clinical notes.
- And phenotyping is the process of turning the raw patient data into psychiatric concepts or phenotypes, utilizing computational power and clustering machine learning algorithms.
The advantages of computational phenotyping over traditional phenotyping is that computational phenotyping is not restrained by the limited DSM-5 informed classifications conferred by psychiatrists, and instead relies directly on the raw patient data to utilize computational power and unsupervised learning to find the new psychiatric disorders/phenotypes. This then can lead to improved (more valid) psychiatric diagnosis and hence improved treatments.
Patient Similarity
When treating patients, doctors often compare the current patient to past patients they have seen, also known as case-based reasoning. Patient similarity is about simulating the doctor’s case-based reasoning using computer algorithms. Instead of depending on one doctor’s memory, wouldn’t it be nice if we can leverage all the patient data in the entire database?
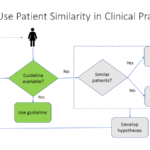
Use Case 3: let’s compare a patient in the clinic to all patients in the hospital database using computer algorithms (see Figure 3 below):
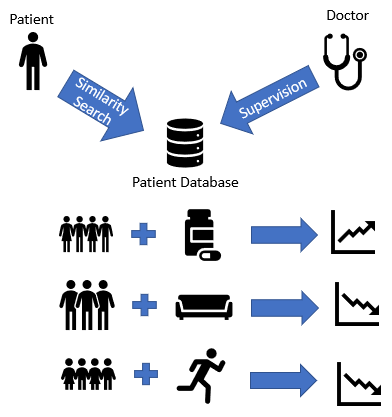
So when the patient comes in, the psychiatrist does an examination of the patient. Then, based on that information, the psychiatrist can do a similarity search through the database. The computer algorithm then provides a list of those potentially similar patients, then the psychiatrist can provide some supervision on that result to find those truly similar patients through this specific clinical context. Then, we can group those patients based on what treatment they are taking and look at what outcome they are getting. Finally, the psychiatrist can recommend the treatment with the best outcome to the current patient, based on this Patient Similarity search utilizing computer machine learning algorithms.
Summary
In summary, AI and Big Data in Psychiatry can be implemented now, starting with the three psychiatric use cases discussed in this article. Although we have a long way to go before we can reach the fictional expertise of Dr. Susan Calvin and the creation of human-like AIs in I, Robot, we can start using AI in clinical psychiatry now to improve psychiatric diagnosis and treatment.