
 This project entails the analysis of a dataset of historical lottery draws between 2009 and 2017 inclusive, scraped from the website of a lottery by my colleague, Gregory Horne. We had a question whether the winning numbers could be predicted, based on past draws, but needed to know if the winning numbers clustered, or were randomly drawn.
This project entails the analysis of a dataset of historical lottery draws between 2009 and 2017 inclusive, scraped from the website of a lottery by my colleague, Gregory Horne. We had a question whether the winning numbers could be predicted, based on past draws, but needed to know if the winning numbers clustered, or were randomly drawn.
In this lottery, ping-pong balls are labeled with one number, ranging from 1 to 49. One of each number is placed in a barrel. The barrel is spun to mix up all the balls, then one ball is drawn. This is repeated 5 more times for a winning number set of 6 winning numbers. In addition, there is a bonus draw, which gives 7 winning numbers.
We will first analyze the winning numbers from 2009 to 2015, then add the winning numbers from 2016 to 2017, to see how the analysis is changed with new data. Thus, we will analyze two lottery datasets, one from 2009 to 2015, and the other from 2016 to 2017.
We propose to perform cluster analysis on this lottery dataset. We hypothesize that the cluster analysis should be random, and therefore the datapoints should plot in a uniform manner in the feature space. This hypothesis is based on the premise that this specific lottery draw is indeed random in nature. However, if our analysis leads to clustering that is significant, then this can lead to further analysis and speculation on the method of determining winners for this specific lottery.
Please click on the following link for the detailed analysis: Lottery analysis.
photo credit: chrisjtse 41:366:2016 via photopin (license)
Related Posts
 Data Scientist Career Path after Formal Education and Training
Data Scientist Career Path after Formal Education and Training Texas Longhorns Football Blue-Chip Ratio 2021- Updated
Texas Longhorns Football Blue-Chip Ratio 2021- Updated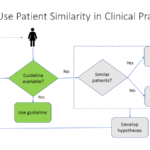 AI in Psychiatry: Patient Similarity in Clinical Practice
AI in Psychiatry: Patient Similarity in Clinical Practice AI and Big Data in Psychiatry: Realistic Use Cases and the Future
AI and Big Data in Psychiatry: Realistic Use Cases and the Future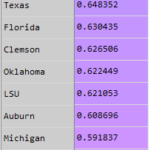 2020 Blue Chip Ratio
2020 Blue Chip Ratio Texas Longhorns Football Blue-Chip Ratio 2020
Texas Longhorns Football Blue-Chip Ratio 2020