
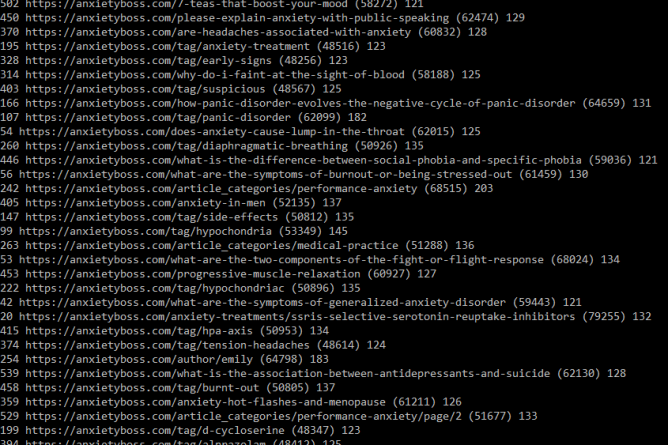
 Today, I will demonstrate a webcrawl and pagerank of a website. For the parser, I’m using a python code, spider.py, which incorporates BeautifulSoup, a Python library for pulling data out of HTML and XML files. I’ll limit the amount of pages to crawl to 100, and will crawl the website AnxietyBoss.com, a leading website for anxiety, and a rather large website with 1000’s of web posts. Here is a snippet of the webcrawl:
Today, I will demonstrate a webcrawl and pagerank of a website. For the parser, I’m using a python code, spider.py, which incorporates BeautifulSoup, a Python library for pulling data out of HTML and XML files. I’ll limit the amount of pages to crawl to 100, and will crawl the website AnxietyBoss.com, a leading website for anxiety, and a rather large website with 1000’s of web posts. Here is a snippet of the webcrawl:
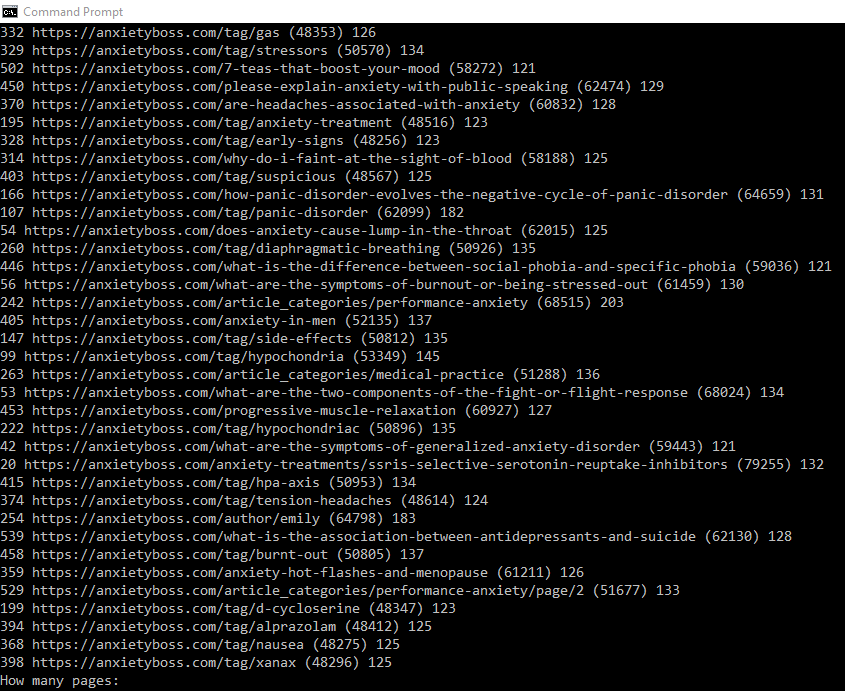
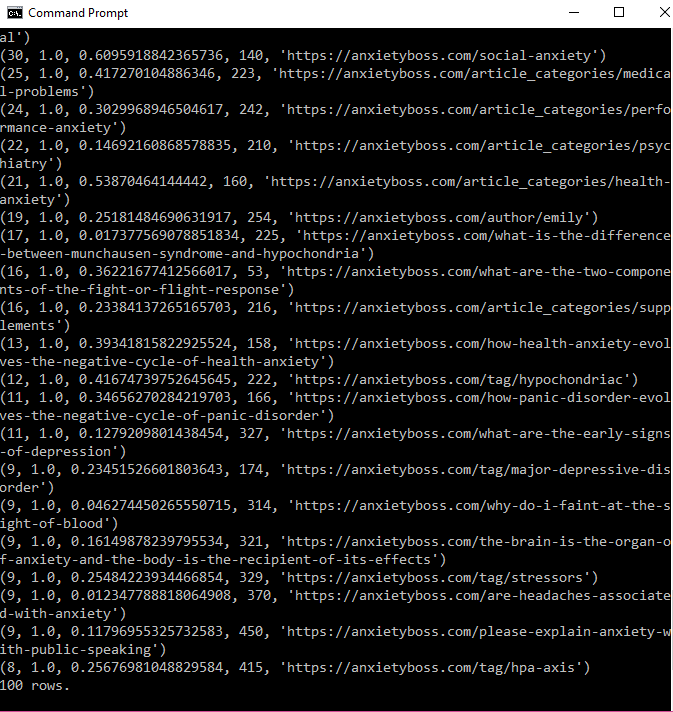
After running the spider.py script, I also ran a pagerank script, sprank.py, to rank the links that were crawled, based on the links going to that link, and ranking the pages based on the number and quality of the links. I went through 100 iterations. Here is a snippet of running the page ranking script:
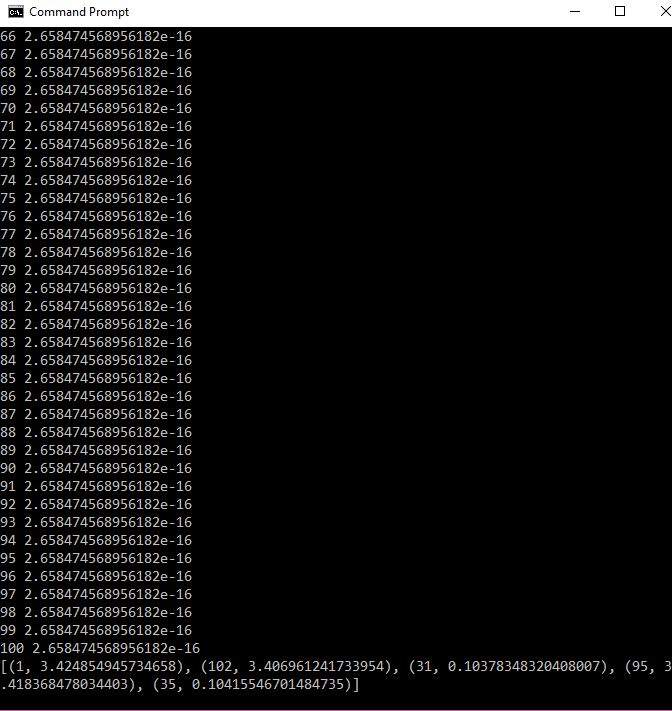
Next, I use spdump.py to visualize the pageranks of the links crawled:
Finally, I further visualize the top 25 links using force.html:
You can play around with this visual by dragging the nodes (balls) around on the screen, to see their connections to other nodes (links) in different configurations. You can also click on each of the nodes to go to the specific link.
This project was performed as part of a capstone project for a Python certification course. All materials in this project are open source, with credits below.
Photo credit: kolacc20 Very simplified PageRank distribution graph via photopin (license).
Source codes and scripts credit: spider.py, sprank.py, spdump.py, force.js, force.css, and force.html obtained from www.py4e.com/materials under the Copyright Creative Commons Attribution.
Related Posts
 Data Scientist Career Path after Formal Education and Training
Data Scientist Career Path after Formal Education and Training Texas Longhorns Football Blue-Chip Ratio 2021- Updated
Texas Longhorns Football Blue-Chip Ratio 2021- Updated AI in Psychiatry: Patient Similarity in Clinical Practice
AI in Psychiatry: Patient Similarity in Clinical Practice AI and Big Data in Psychiatry: Realistic Use Cases and the Future
AI and Big Data in Psychiatry: Realistic Use Cases and the Future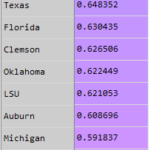 2020 Blue Chip Ratio
2020 Blue Chip Ratio Texas Longhorns Football Blue-Chip Ratio 2020
Texas Longhorns Football Blue-Chip Ratio 2020
Good day i noticed the page crawl spider.py is going on for a long time is it supposed to do that